When the map function starts producing output, it is not simply written to disk. The process is more involved, and takes advantage of buffering writes in memory and doing some presorting for efficiency reasons.Each map task has a circular memory buffer that it writes the output to. The buffer is 100 MB by default, it can change based on the size.When the contents of the buffer reaches a certain threshold size 80%,a background thread will start to spill the contents to disk,during this time, the map will block until the spill is complete.
The Mapper reads data in the form of key/value pairs and It outputs zero or more key/value pairs.
MapReduce Flow-The Mapper
Each of the portions (RecordReader, Mapper, Partitioner,Reducer, etc.)
The map output file is sitting on the local disk of the machine.The reduce task needs the map output for its particular partition from several map tasks across the
cluster. The map tasks may finish at different times, so the reduce task starts copying their outputs as soon as each completes. This is known as the copy phase of the reduce task,by default 5 threads can copy,this we can change by property.
When all the map outputs have been copied, the reduce task moves into the sort phase.For example, if there were 50 map outputs, and the merge factor was 10.then there would be 5 rounds. Each round would merge 10 files into one, so at the end there would be five intermediate files.final round that merges these five files into a single sorted file and move to the reduce phase.The output of this phase is written directly to the output filesystem, typically HDFS.
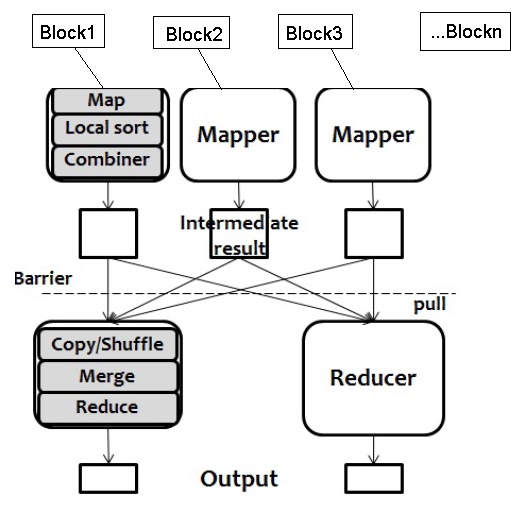
- There may be a single Reducer, or multiple Reducers
- This is specified as part of the job configuration
- All values associated with a particular intermediate key are guaranteed to go to the same Reducer
- The intermediate keys, and their value lists, are passed to the Reducer in sorted key order
- This step is known as the ‘shuffle and sort’
- These are written to HDFS
- In practice, the Reducer usually emits a single key/value pair for each input key
- Each of the portions (Reducer,RecordWriter,output file)
No comments:
Post a Comment